Valley Family: Exploring Scalable Vision-Language Design for Multimodal Understanding and Reasoning

🎮️ Github Repository |
🤗 Huggingface Model Collection |
📙 Technical Report
News
- [2026/05/05] 🔥🔥🔥 We have released the technical report of Valley3! Check out the full paper here: Valley3 Technical Report.
- [2026/05/01] 🔥🔥🔥 We have released the model weights of Valley3, which is an omni foundation model collection for unified e-commerce understanding and reasoning.
- [2025/11/27] 🔥🔥 We have released the technical report of Valley2.5! Check out the full paper here: Valley2.5 Technical Report.
- [2025/10/26] 🔥🔥 We have released the weights of Valley2.5, which significantly enhances multimodal understanding and reasoning capabilities. It has achieved 74.3 on the OpenCompass Multi-modal Academic Leaderboard!
Introduction
Valley is a cutting-edge multimodal large model designed to handle a variety of tasks involving text, images, and video data, which is developed by ByteDance. Our model:
- Achieved the best results in the inhouse e-commerce and short-video benchmarks, much better then other SOTA opensource models.
- Demonstrated comparatively outstanding performance in the OpenCompass Benchmark.
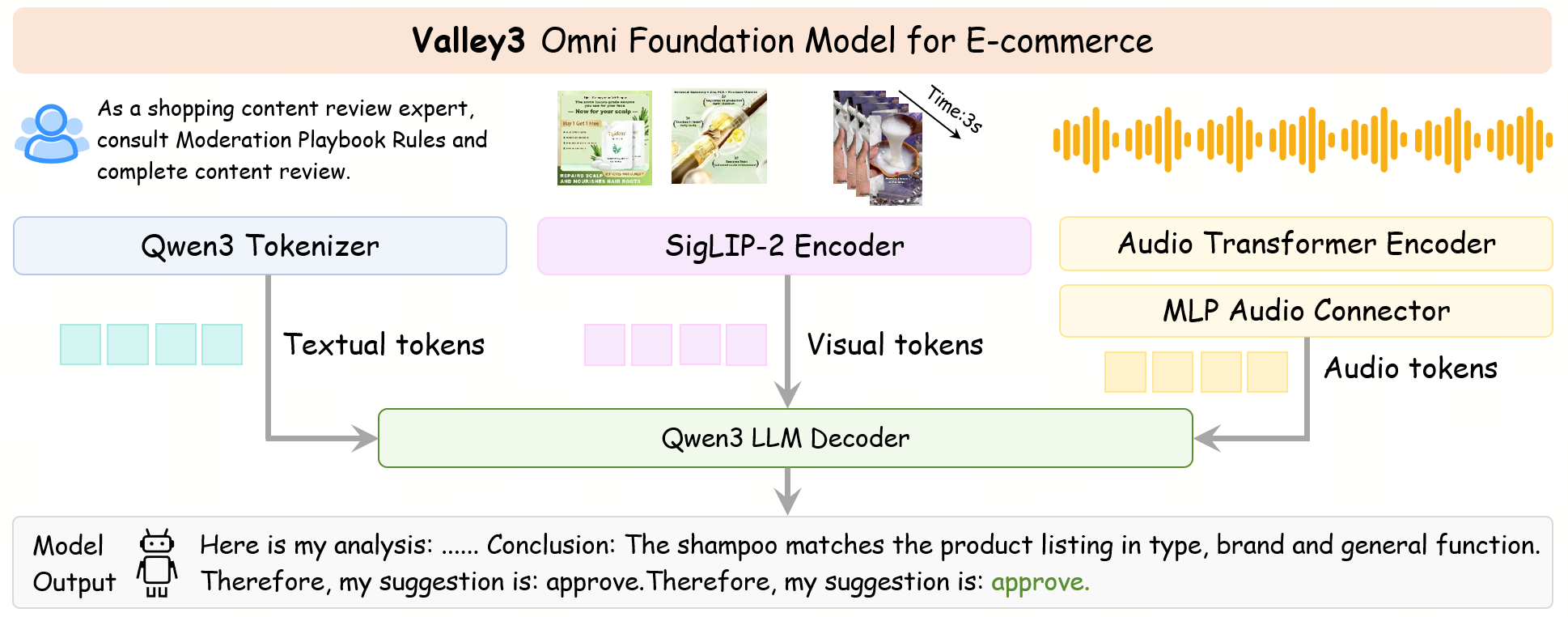
Valley3
Valley3 is built upon the Qwen3-VL backbone and extends it with audio transformer for audio encoding. The audio embeddings are aligned to the visual-language backbone via an MLP-based connector, then concatenated with visual and text tokens into a unified input space, enabling omni-modal understanding.
Environment Setup & Inference Demo
Please refer to the detailed instruction in Github: Valley3 repository.
