
KAI Large Language Models
Collection
All of the KAI LLMs in one collection. The KAI models are a series of lightweight LLMs ranging from 1 Billion parameters to 7 Billion parameters • 5 items • Updated • 2
KAI-7B

KAI-7B Large Language Model (LLM) is a fine-tuned generative text model based on Mistral 7B. With over 7 billion parameters, KAI-7B outperforms its closest competetor, Meta-Llama 2 70b, in all benchmarks we tested.

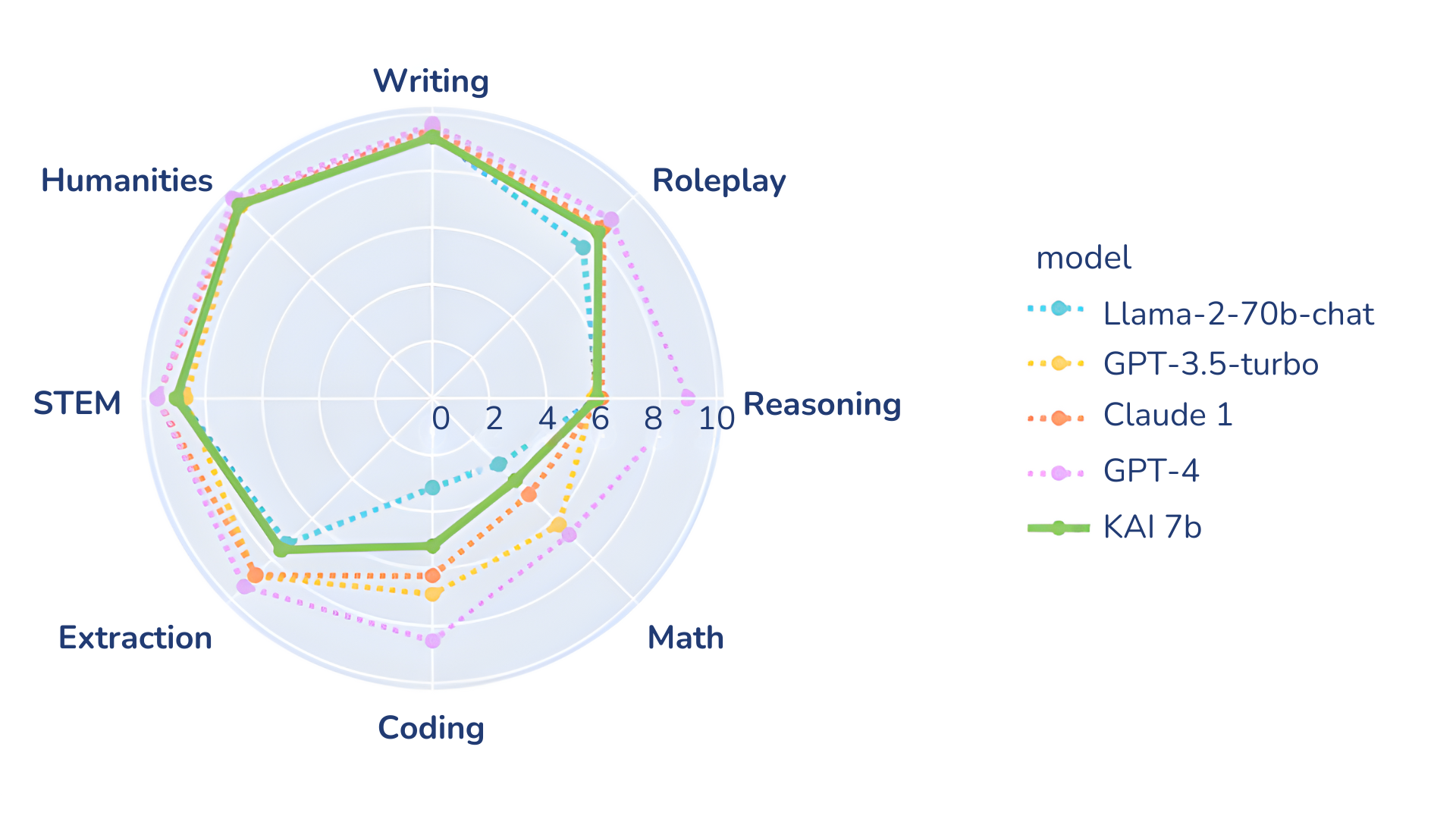
As you can see in the benchmark above, KAI-7B excells in STEM but needs work in the Math and Coding fields.
KAI-7B is a pretrained base model and therefore does not have any moderation mechanisms.
KAI-7B is governed by the apache 2.0 liscense, and therefore means that whatever the license deems unacceptable shall not be allowed. We specificaly ban the use of ANY AND ALL KAI MODELS for hate speech towards a paricular thing, person, our particular group due to legal and ethical issues.