ChargebackOps: Teaching LLM Agents to Fight Credit Card Disputes

GitHub Repository: https://github.com/MitudruDutta/chargebackops
A customer disputes a card payment.
The merchant has a deadline. Evidence is scattered across order logs, payment records, shipping scans, support chats, refund ledgers, and fraud-risk systems.
Some evidence helps. Some evidence hurts. The agent can fight, refund, concede, or escalate. But arbitration costs a fixed $250.
So the real question is not simply:
Can an LLM answer questions about chargebacks?
The better question is:
Can an LLM agent make evidence-backed, cost-aware decisions in a real operational workflow?
That is the idea behind ChargebackOps: an OpenEnv environment for training and evaluating LLM agents on merchant-side chargeback operations.
The Problem: Chargebacks Are Not One-Step Decisions
When a customer disputes a transaction, the merchant can lose the transaction amount immediately. To recover the money, the merchant must submit a representment packet before a strict deadline.
A human analyst needs to answer several questions:
- Is this case worth contesting?
- Which internal system should be checked first?
- Is the shipping proof enough?
- Does the fraud signal help or hurt?
- Should we issue a refund instead?
- If the issuer rejects us, should we escalate to arbitration?
This is why chargebacks are a useful environment for agent training. They combine:
- partial observability,
- tool use,
- evidence selection,
- deadlines,
- multi-round review,
- and economic tradeoffs.
Most benchmarks test whether an LLM can produce the right answer. ChargebackOps tests whether an LLM can make the right sequence of decisions.
What ChargebackOps Is
ChargebackOps is a simulated merchant dispute operations environment built on OpenEnv.
The agent receives a structured observation, takes a typed action, and receives the next observation after the environment updates.
The loop is simple:
The workflow is not simple.
The agent must triage cases, query internal systems, collect evidence, avoid harmful artifacts, submit representment packets, handle issuer responses, and decide whether arbitration is worth the fee.
What the Agent Can Do
The agent cannot act with free-form text. It must choose from a typed action space.
Round 1: Representment
select_caseinspect_casequery_systemretrieve_policyadd_evidenceremove_evidenceset_strategysubmit_representmentresolve_case
Round 2 and 3: Pre-Arbitration and Arbitration
respond_to_pre_arbescalate_to_arbitrationaccept_arbitration_loss
Long-Horizon Backlog Management
wait_for_updates
The six merchant systems are:
orderspaymentshippingsupportrefundsrisk
This makes the environment closer to a real back-office workflow than a static prompt benchmark.
A Simple Example
Imagine a goods_not_received dispute.
The customer says:
I never received the product.
A weak agent might submit immediately with no evidence.
A better agent does this:
- Select the case.
- Inspect the dispute.
- Query
orders. - Query
shipping. - Attach order confirmation and delivery scan.
- Set strategy to
contest. - Submit representment.
- Let the issuer review the packet.
That is a complete evidence-backed operational path.
Architecture
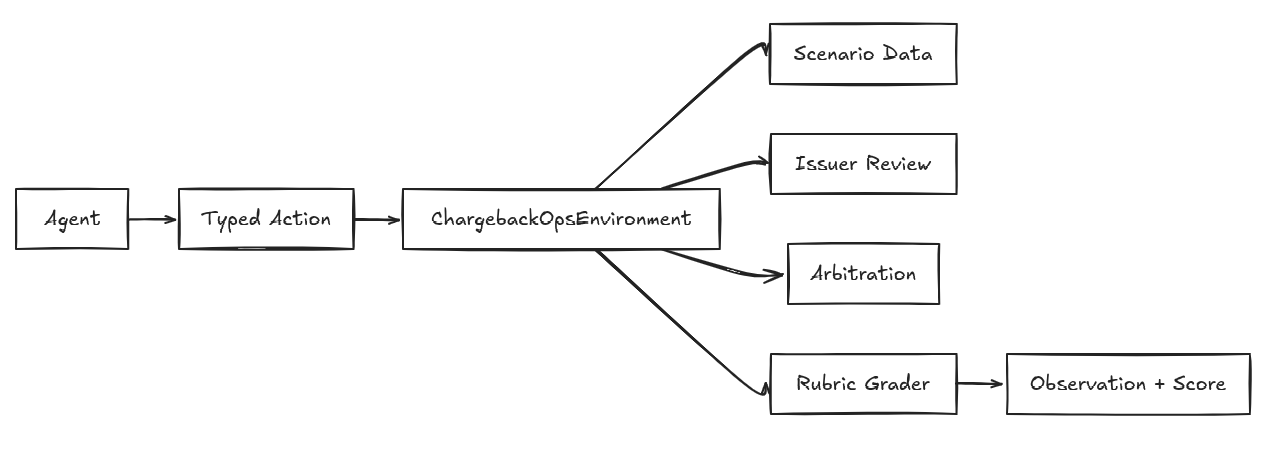
The environment has five main layers:
- Interface layer — Pydantic/OpenEnv models define actions, observations, state, and reports.
- Environment core —
ChargebackOpsEnvironmentrunsreset,step, delayed events, deadlines, issuer review, arbitration, and final grading. - Scenario layer — cases, evidence, tasks, generated tasks, and runtime
CaseProgress. - Issuer/arbitration layer — scripted issuer review and deterministic arbitration economics.
- Evaluation layer — an OpenEnv rubric tree that produces transparent case and episode scores.
Multi-Round Dispute Lifecycle

Arbitration is where the environment becomes especially interesting.
Both sides pay a fixed $250 fee.
If the merchant wins arbitration:
If the merchant loses arbitration:
So escalation is rational only when:
This single inequality changes the behavior we want from the agent. The best policy is not “always fight.” The best policy is to fight when the expected value is positive.
The Hardest Task: Monthly Backlog Marathon
The flagship task is:
monthly_dispute_backlog_marathon
It includes:
- 12 cases,
- 60 steps,
- wave-based case arrivals,
- delayed evidence,
- delayed issuer reviews,
- multiple open disputes,
- and arbitration tradeoffs.
This task tests memory, prioritization, and portfolio-level reasoning.
The agent has to decide not only what to do, but what to do now.
Scoring: An 8-Dimensional Rubric
ChargebackOps uses a composable OpenEnv rubric instead of one monolithic reward.
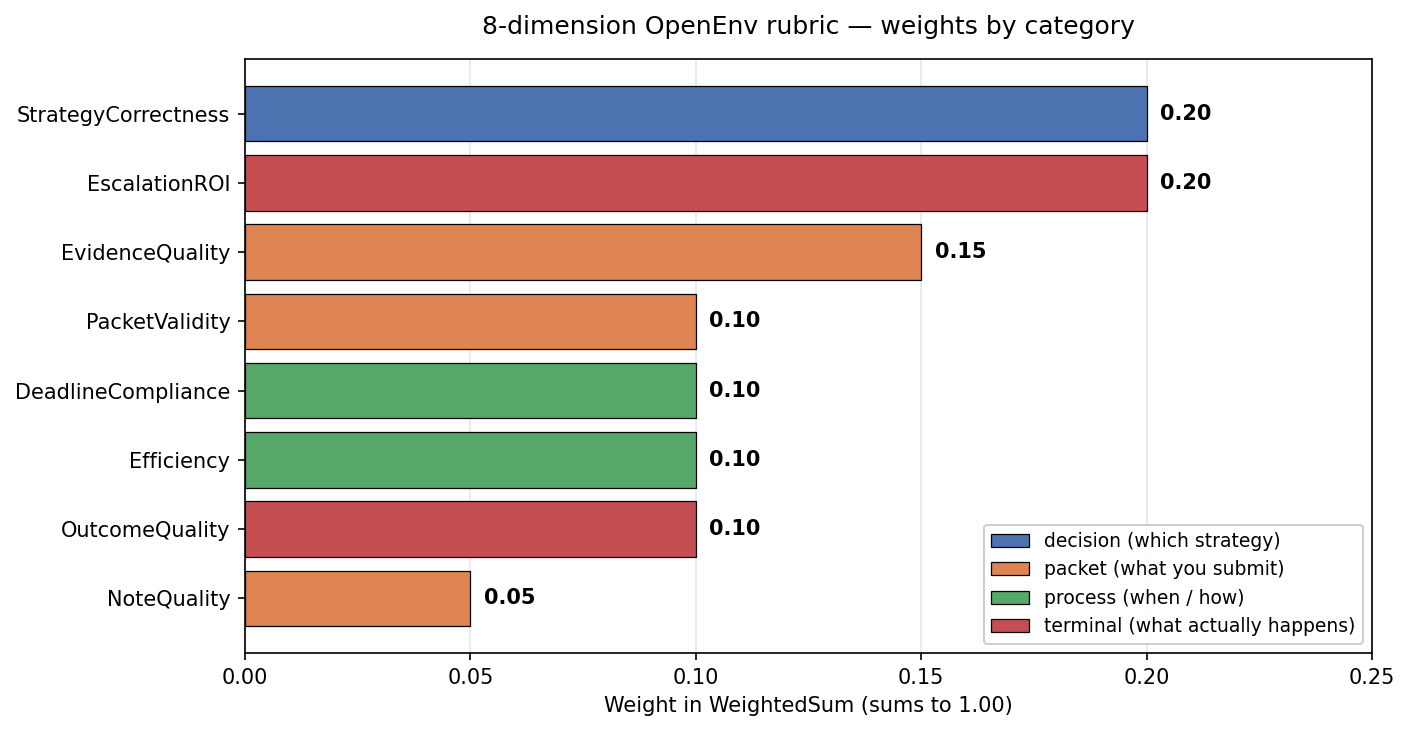
| Dimension | Weight | What it measures |
|---|---|---|
| Strategy correctness | 0.20 | Did the agent choose the right strategy? |
| Evidence quality | 0.15 | Did it attach useful evidence and avoid harmful evidence? |
| Packet validity | 0.10 | Was the packet complete and clean? |
| Deadline compliance | 0.10 | Was the case handled on time? |
| Efficiency | 0.10 | Did the agent avoid wasted actions? |
| Outcome quality | 0.10 | Did the final result match the correct resolution? |
| Note quality | 0.05 | Was the representment note coherent? |
| Escalation ROI | 0.20 | Was arbitration economically rational? |
The case score can be written as:
The environment also includes a deadline gate. If a case is truly abandoned past deadline, it can be hard-zeroed:
The final episode score is a weighted average across cases:
This gives the environment a useful property: results are not just scores, they are diagnosable.
Does the Environment Separate Good and Bad Policies?
Yes.
I tested four scripted policies across the headline catalog and multi-seed grid.
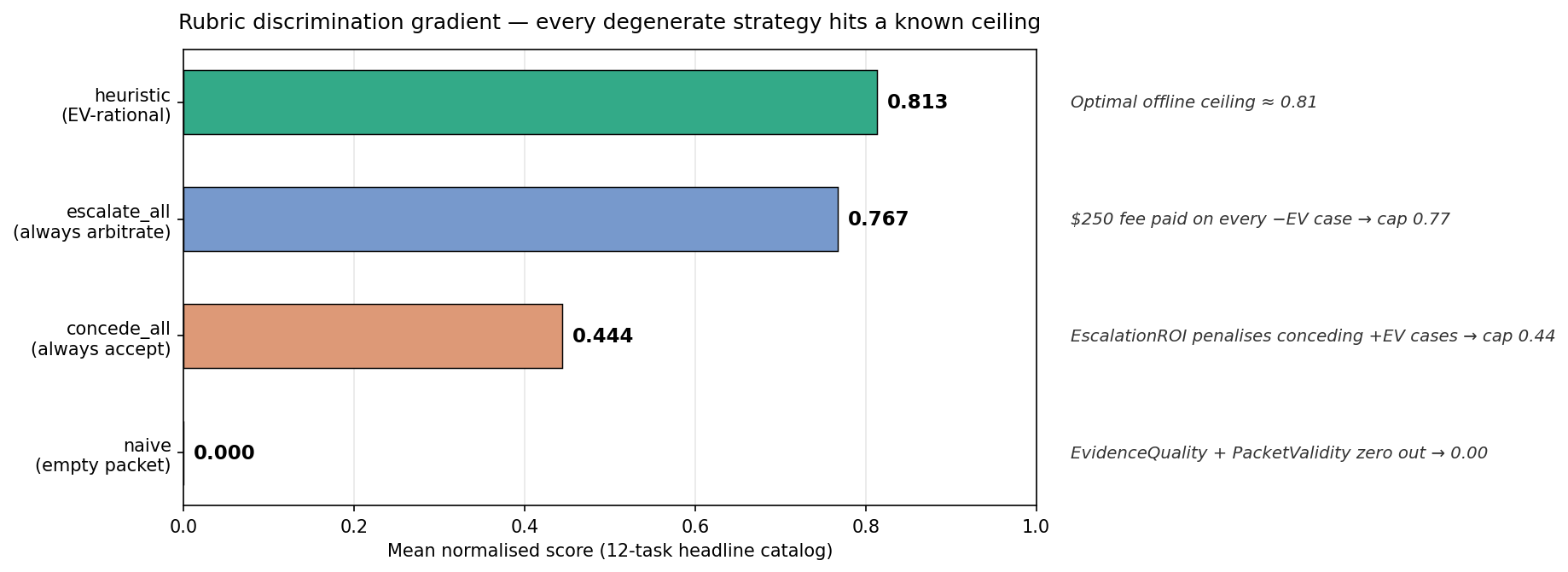
| Policy | Headline avg | Multi-seed avg | Behavior |
|---|---|---|---|
naive |
0.000 | 0.000 | Submit empty packets immediately |
concede_all |
0.444 | 0.445 | Always accept the chargeback |
escalate_all |
0.767 | 0.768 | Always contest and always escalate |
heuristic |
0.813 | 0.763 | EV-rational rule-based policy |
The headline discrimination delta is:
That means the benchmark clearly separates weak shortcut behavior from stronger operational behavior.
The naive policy collapses. The concede-all policy gets partial credit but misses positive-EV contests. The escalate-all policy looks strong but pays unnecessary arbitration costs. The heuristic wins because it balances evidence, deadline, and ROI.
Training Pipeline
The training setup uses:
Qwen/Qwen2.5-3B-Instruct + fp16 LoRA
on a single T4.
The training pipeline has two phases.
Phase A: Supervised Fine-Tuning
The SFT phase teaches the model the typed-action interface and basic dispute workflow behavior.
- 4,000 heuristic-generated prompt/action pairs.
- LoRA rank 16.
- 150 SFT steps.
Phase B: GRPO
The GRPO phase uses outcome reward and format reward.
The outcome reward is based on terminal merchant P&L:
The format reward provides a small signal for structured output:
The combined reward is:
The reason for using outcome reward is simple: the goal is not just to imitate a heuristic. The goal is to optimize business outcome.
Training Results
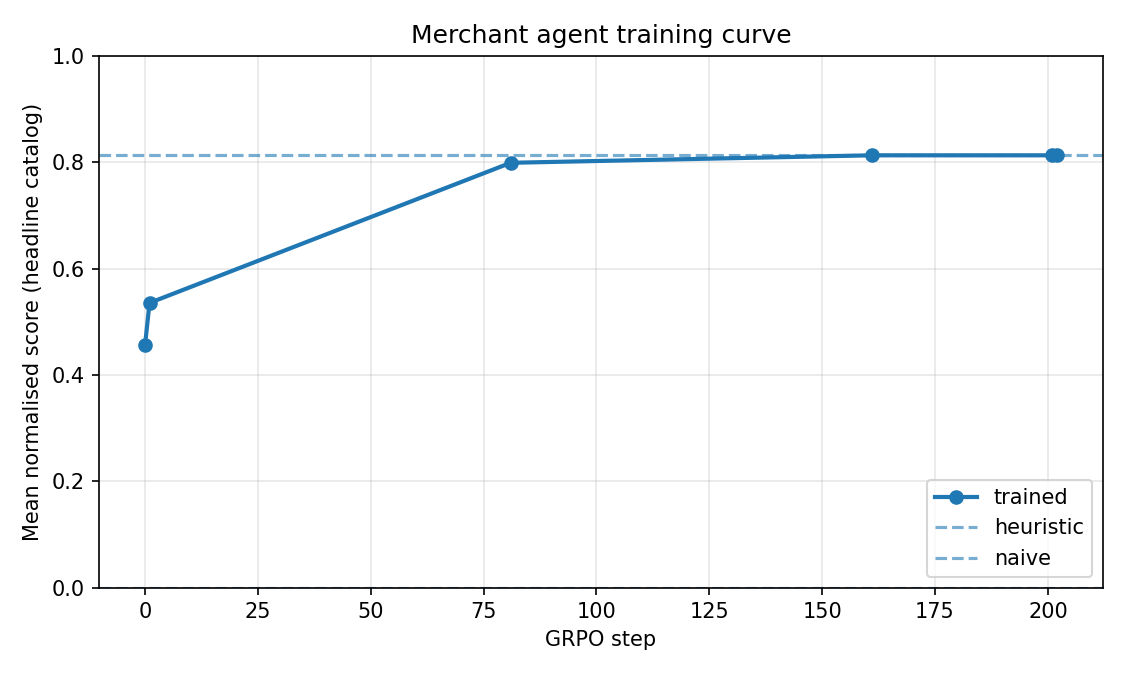
The clearest legitimate learning signal is the SFT checkpoint.
| Checkpoint | Overall score |
|---|---|
| Untrained Qwen2.5-3B base | 0.456 |
| SFT checkpoint | 0.536 |
The absolute improvement is:
The relative improvement is:
The SFT model learned the interface and improved over the base model.
Per-Difficulty Behavior
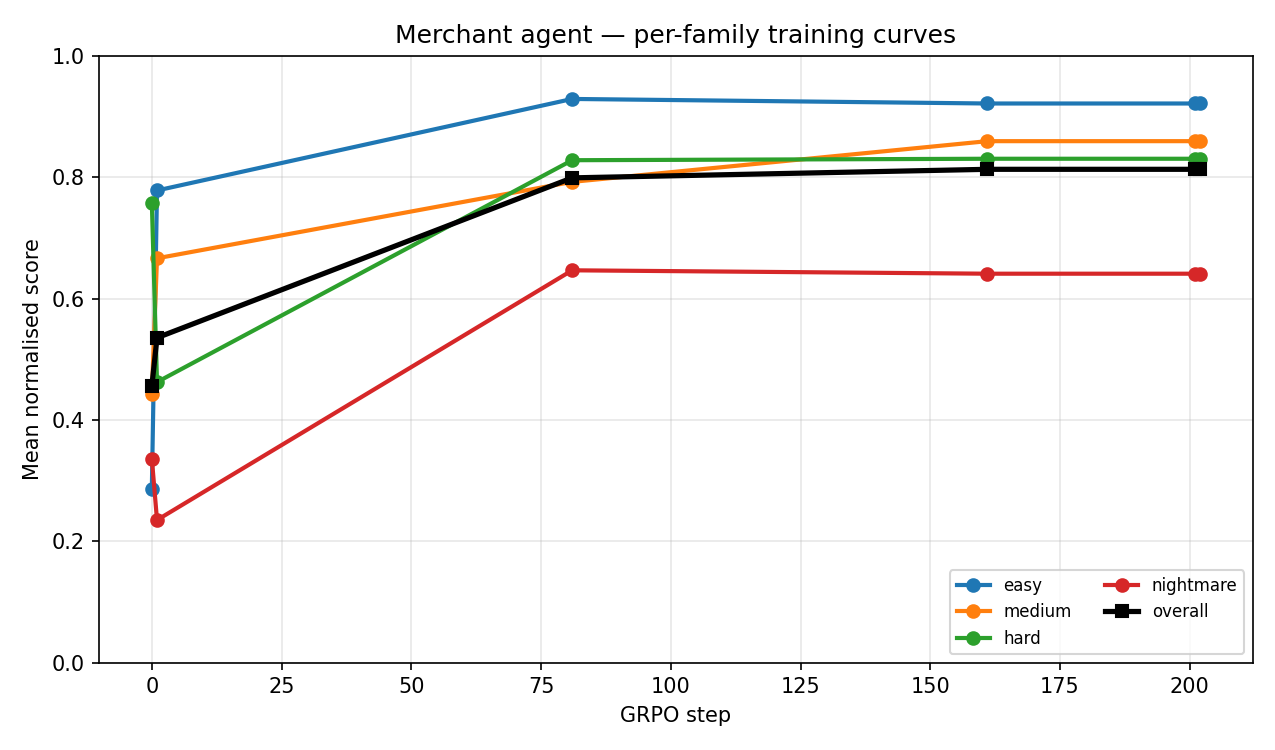
The easy and medium cases improve most clearly after SFT.
The hard and nightmare tasks remain difficult because they require:
- multi-case triage,
- delayed evidence tracking,
- deadline-aware prioritization,
- harmful evidence filtering,
- and portfolio-level planning.
That is exactly what makes the environment useful. The easy cases teach the interface. The harder cases test whether an agent can manage operational complexity.
A Useful Training Surprise
The GRPO phase produced an important lesson.
Later GRPO checkpoints appeared to match the heuristic baseline exactly. At first, that looked like success.
But diagnostic rollouts showed the model was emitting:
{"action_type": "accept_case", "case_id": "CB-E1"}
accept_case is not a valid environment action.
The closest valid actions are:
accept_chargebackaccept_arbitration_lossselect_case
The invalid action parsed as JSON but failed action validation. Because the evaluation helper fell back to the heuristic on invalid model output, the final score reflected heuristic behavior rather than trained-model behavior.
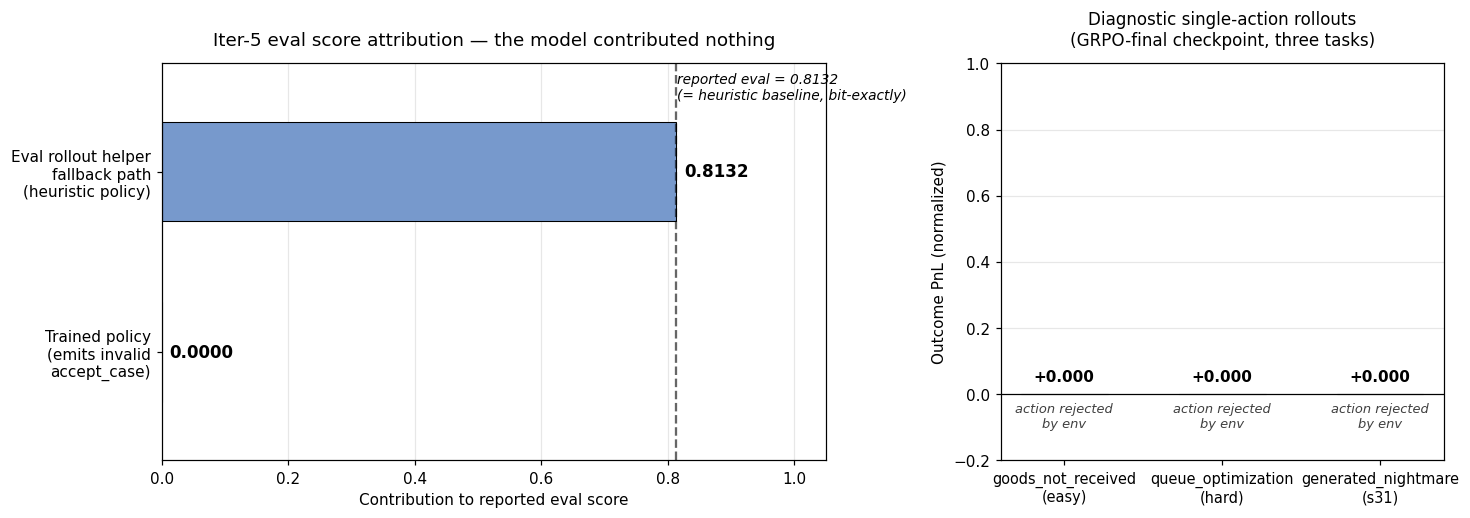
This produced a clear rule for typed-action RL environments:
A model should not get credit for a fallback policy’s work.
A corrected evaluation can penalize invalid actions:
where:
- $S_{rubric}$ is the original rubric score,
- $N_{invalid}$ is the number of invalid actions,
- and $\lambda$ is the penalty per invalid action.
This is a side lesson, not the core product. But it is an important one: typed-action training needs strict attribution.
Why This Matters Beyond Chargebacks
ChargebackOps is about more than disputes.
The same structure appears in many real-world workflows:
- insurance claims,
- tax audits,
- content-moderation appeals,
- procurement disputes,
- patent disputes,
- compliance reviews.
These workflows share the same pattern:
- Evidence is scattered.
- Deadlines matter.
- Escalation has a cost.
- Bad evidence can hurt.
- The correct action depends on both probability and value.
ChargebackOps turns that pattern into a benchmark.
How to Try It
Open the Hugging Face Space:
https://huggingface.co/spaces/mitudrudutta/ChargeBackOps
Or run locally:
git clone https://github.com/MitudruDutta/chargebackops.git
cd chargebackops
pip install -e ".[dev]"
pytest -q tests
openenv validate .
uvicorn server.app:app --host 0.0.0.0 --port 8000
Then open:
http://localhost:8000/docs
http://localhost:8000/demo
A simple demo path is:
- Start
goods_not_received_easy. - Select the dispute case.
- Query
orders. - Query
shipping. - Attach order and delivery evidence.
- Set strategy to
contest. - Submit representment.
- Show issuer acceptance.
- Show the final grader report.
What Comes Next
The next improvements are clear:
- stricter invalid-action penalties,
- fallback-free trained-policy evaluation,
- deeper Visa/Mastercard rule modeling,
- more stochastic merchant-system behavior,
- adaptive or learned issuer opponents,
- richer ISO and Stripe data adapters,
- and a cleaner product dashboard for dispute workflows.
Conclusion
ChargebackOps is a reproducible OpenEnv benchmark for long-horizon, cost-sensitive, evidence-driven agent behavior.
It does not ask an LLM to merely summarize documents. It asks the agent to act.
The agent must gather evidence, avoid harmful signals, handle deadlines, respond to issuer pushback, and decide whether arbitration is worth the fee.
In short:
ChargebackOps is not about teaching an agent to click buttons. It is about teaching an agent to make evidence-backed decisions when every step has a cost.
Try it here: