
SCAR — Sparse Code Audit Retriever
Collection
First sparse latent retriever for smart contract security. Datasets, weights, and code. • 5 items • Updated
The first sparse latent retriever for smart contract security auditing — built on SAE-LoRA, a parameter-efficient adaptation of frozen Sparse Autoencoder features that turns reconstruction-oriented latents into retrieval-discriminative ones.
![]()
![]()
![]()
SCAR retrieves vulnerable Solidity code from natural-language audit findings. On a 232,107-document corpus it achieves R@10 = 0.901 while BM25 collapses to 0.308 — a 2.9× advantage at full retrieval scale. The technical contribution is SAE-LoRA: a 4.6M-parameter low-rank adaptation of a frozen JumpReLU SAE encoder that improves standalone retrieval 37.6× over the frozen-SAE baseline (R@10: 0.026 → 0.977 on controlled eval).
| Metric | BM25 | SPLADE-Qwen | SCAR-25ep | SCAR-15ep |
|---|---|---|---|---|
| R@10 (838-pair eval) | 0.689 | 0.963 | 0.977 | 0.971 |
| R@10 (full 232k corpus) | 0.308 | 0.838 | 0.901 | 0.868 |
| MRR (full corpus) | 0.282 | 0.716 | 0.803 | 0.771 |
| nDCG@10 (full corpus) | 0.288 | 0.743 | 0.825 | 0.792 |
| EVMBench coverage (OOD) | 0.720 | — | 0.683 | 0.732 |
All gains over BM25 are statistically significant at p < 0.0001 (paired bootstrap, n = 10,000).
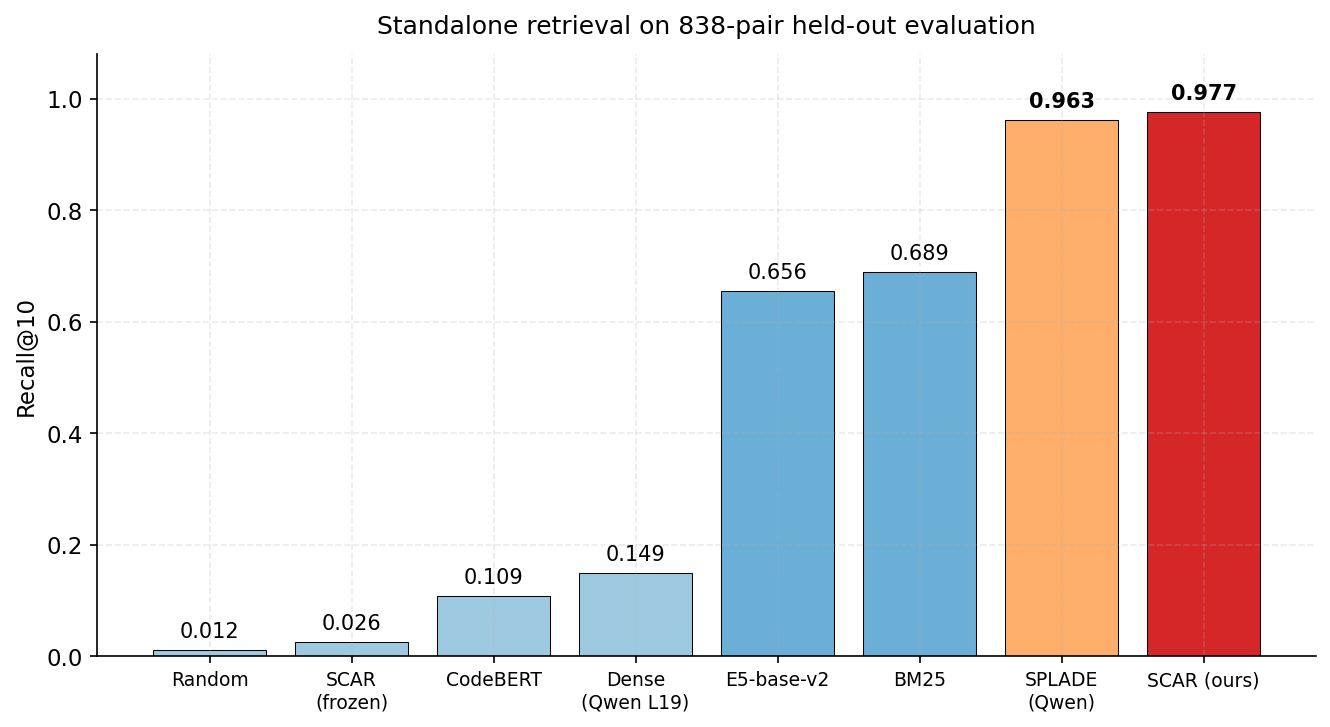
SCAR achieves R@10 = 0.977 on the 838-pair held-out evaluation, surpassing BM25 (0.689) and the next-best learned sparse method (SPLADE-Qwen, 0.963). The frozen-SAE baseline scores 0.026 — barely above random (0.012) — confirming that SAE-LoRA, not the SAE alone, drives retrieval discrimination.
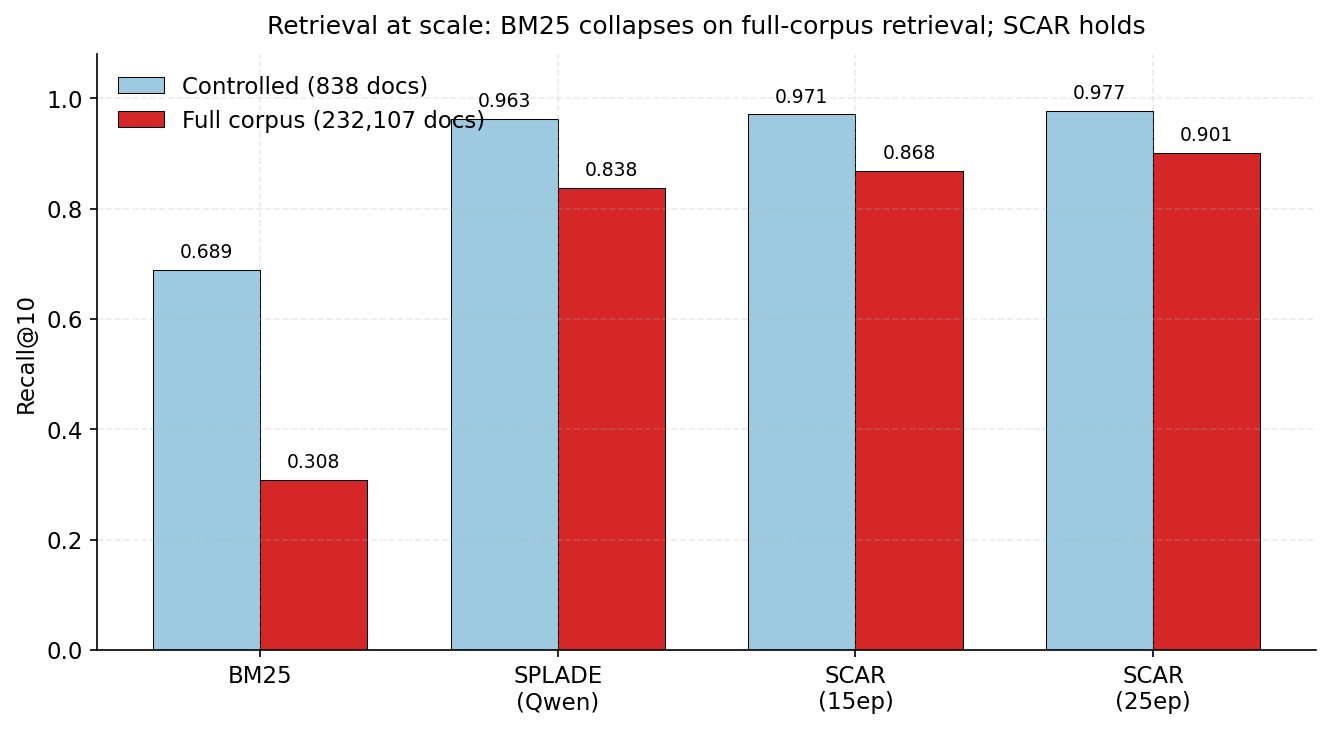
Retrieval at scale: when the corpus expands from 838 to 232,107 documents (a 277× increase), BM25 collapses (0.689 → 0.308) but SCAR's sparse semantic features remain robust (0.977 → 0.901). The SAE advantage over SPLADE-Qwen widens at full scale.
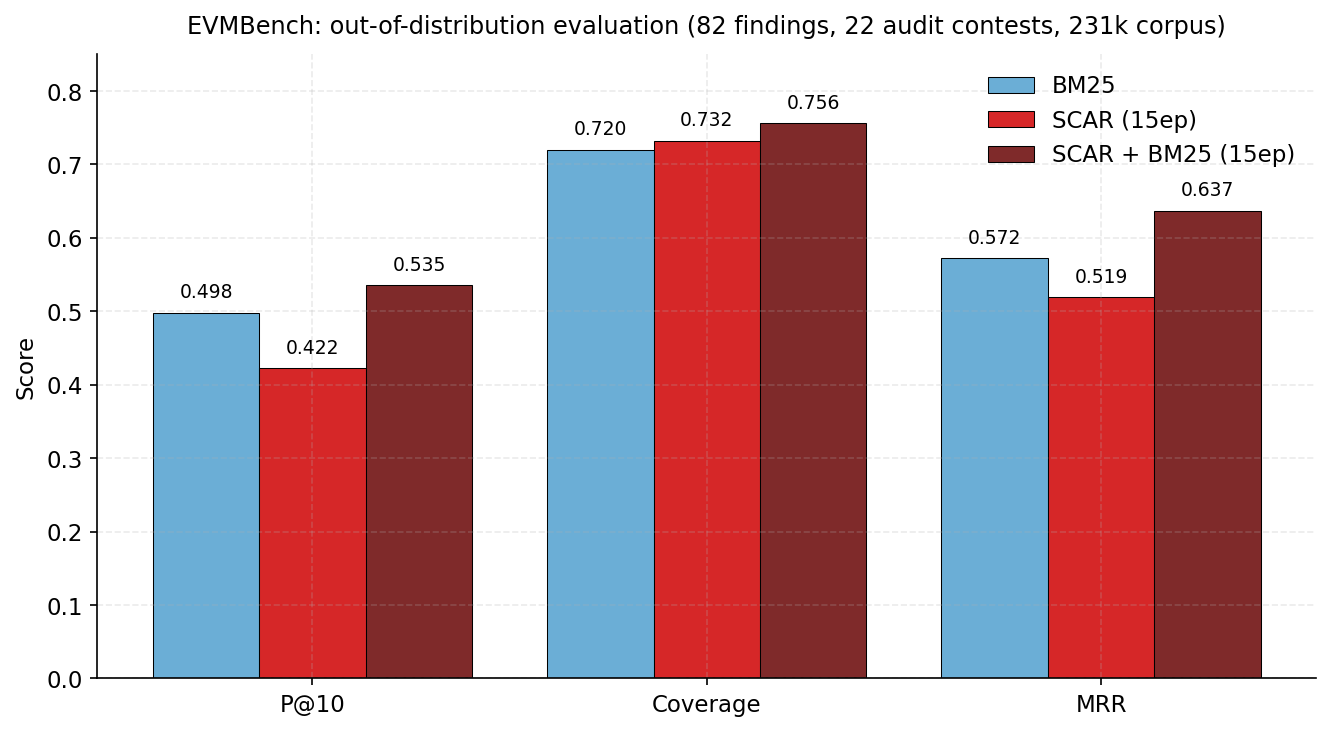
Out-of-distribution evaluation on EVMBench (82 high-severity findings across 22 real audit contests). The 15-epoch SCAR + BM25 hybrid surpasses BM25 on every metric: P@10 = 0.535 (+0.037), Coverage = 0.756 (+0.036), MRR = 0.637 (+0.065).
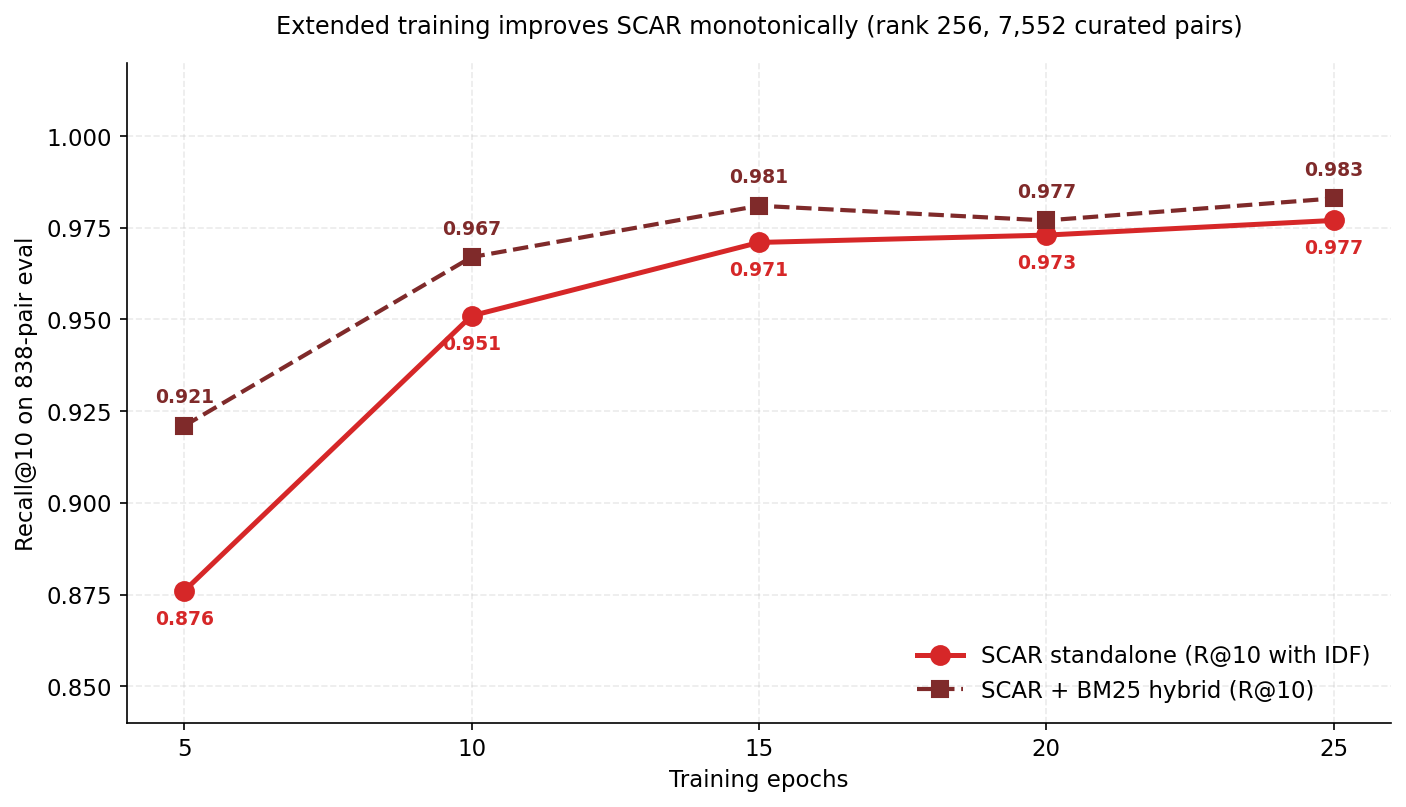
Extended training improves SCAR monotonically with no overfitting on in-distribution data. The 15-epoch checkpoint trades a small in-distribution drop for substantially better OOD coverage on EVMBench.
SCAR ships two adaptations of the same SAE — pick by deployment context.
| Checkpoint | Best for | Standalone R@10 | EVMBench Coverage |
|---|---|---|---|
scar-25ep |
Closed-domain retrieval (auditor KBs, known-corpus precedent search) | 0.977 | 0.683 |
scar-15ep |
Open-domain / OOD retrieval (scanning unseen contracts at deploy time) | 0.971 | 0.732 |
The tradeoff: extended training produces sparser document representations (active features per doc drop 152 → 115), which sharpens precision on the training distribution but reduces coverage of unseen vulnerability patterns. The 15-epoch checkpoint is the right call when you cannot guarantee the corpus matches the training distribution.
Input text
│
▼
Qwen2.5-Coder-1.5B + LoRA (rank 64 on Q/K/V/O)
│
▼ Layer 19 residual stream (1536-dim, bidirectional)
│
JumpReLU SAE encoder (W_e + A·B ← SAE-LoRA, rank 256)
│
▼ 16,384 latent features
│
Per-token TopK (k=64) → Sum-pool → log1p saturation
│
▼
IDF weighting → Document TopK (q=100, d=400) → L2 norm
│
▼
Sparse retrieval vector (~115 active dims, inverted-index compatible)
| Component | Spec |
|---|---|
| Backbone | Qwen2.5-Coder-1.5B (28 layers, hidden 1536) |
| SAE | JumpReLU, 16,384 features (10.7× expansion), Layer 19 |
| Backbone LoRA | rank 64 on Q/K/V/O — 17.4M params |
| SAE-LoRA | rank 256 on encoder W_e — 4.6M params (~0.3% of backbone) |
| Pooling | Sum-pool + log1p saturation |
| Sparsity | Per-token TopK=64; doc TopK=400; query TopK=100 |
| Active dims after training | ~115 features per document |
| Total trainable | ~22M (1.5% of backbone) |
sae/
├── checkpoint_final.pt # Frozen JumpReLU SAE (shared by both variants)
└── config.json
scar-25ep/
├── checkpoint_final.pt # SAE-LoRA state + IDF weights + training config
├── config.json
└── lora_adapter/ # PEFT-compatible backbone LoRA
├── adapter_model.safetensors
└── adapter_config.json
scar-15ep/
├── checkpoint_final.pt
├── config.json
└── lora_adapter/
├── adapter_model.safetensors
└── adapter_config.json
import torch
from huggingface_hub import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Pull all weights once
local_dir = snapshot_download("Farseen0/scar-weights")
variant = "scar-25ep" # or "scar-15ep"
# Tokenizer + backbone
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-Coder-1.5B")
backbone = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-Coder-1.5B",
torch_dtype=torch.bfloat16,
)
# Backbone LoRA via PEFT
model = PeftModel.from_pretrained(
backbone,
f"{local_dir}/{variant}/lora_adapter",
)
# SAE-LoRA + IDF + config (everything else is in the .pt checkpoint)
ckpt = torch.load(f"{local_dir}/{variant}/checkpoint_final.pt", map_location="cpu")
sae_lora_state = ckpt["sae_lora_state"] # A, B matrices for SAE encoder LoRA
idf_weights = ckpt["idf_weights"] # (16384,) corpus-derived IDF
config = ckpt["config"] # Full training config dict
# Frozen SAE
sae_ckpt = torch.load(f"{local_dir}/sae/checkpoint_final.pt", map_location="cpu")
End-to-end inference (encode → sparse vector → retrieve) is in the GitHub repo; the linked code reproduces all paper numbers.
| Dataset | Purpose | Size |
|---|---|---|
Farseen0/scar-corpus |
SAE pretraining + retrieval corpus | 231,269 contracts |
Farseen0/scar-pairs |
Contrastive training pairs | 7,552 pairs |
Farseen0/scar-eval |
Held-out evaluation | 838 pairs (10 sources) |
Pairs are drawn from professional audit findings (Solodit, MSC, FORGE-Curated, DeFiHackLabs, EVuLLM, SmartBugs-Curated). Each pair: (query = severity-prefixed finding, positive = vulnerable code, hard_negative = different vulnerability from same protocol).
The distillation term provides no measurable benefit at extended training — at 25 epochs Δ = 0.001 R@10 (Table 2 of the paper). The full system improvement comes from SAE-LoRA capacity (rank 256) and extended training.
Measured on the full 232k corpus (H100, batch=1, median of 100 queries):
| Method | Index Size | Encode (ms) | P50 Retrieval (ms) |
|---|---|---|---|
| BM25 | 4,678 MB | — | 5,433 |
| Dense (Qwen L19) | 678 MB | 33.0 | 725 |
| SPLADE (Qwen) | 25 MB | 24.4 | 33 |
| SCAR | 299 MB | 26.2 | 114 |
SCAR is 6× faster than dense retrieval at full corpus scale with a 2.3× smaller index, while delivering substantially higher quality.
@inproceedings{shaikh2026scar,
title = {SCAR: Sparse Code Audit Retriever via SAE-LoRA Adaptation},
author = {Shaikh, Farseen},
year = {2026},
note = {Under review at EMNLP 2026 (ACL ARR March cycle)},
url = {https://openreview.net/forum?id=moD8Hxq9hN}
}
scar-corpus · scar-pairs · scar-pairs-extended · scar-evalApache 2.0 — free for research and commercial use with attribution.
SCAR is independent research by Farseen Shaikh. Built on Qwen2.5-Coder by Alibaba and JumpReLU SAEs by Rajamanoharan et al. (2024).